Secure Systems Can Still Cause Harm
Bias, toxicity, and governance in modern AI systems
1 Introduction
AI risk has two dimensions: security and safety. Security focuses on attacks against systems. Safety focuses on harm that can arise even when systems behave as designed. For a deeper look at adversarial threats such as prompt injection, privilege escalation, and defense-in-depth controls for autonomous systems, see my article: Securing Agentic AI Systems: A Defense-in-Depth Approach.
A model can be secure from attackers and still produce unfair or harmful outcomes. AI systems learn patterns from historical data, and those patterns often include social bias, stereotypes, and harmful assumptions baked in long before the model was trained.
This is no longer a research problem. AI now influences hiring, lending, healthcare, content moderation, and customer service. When these systems fail, the impact is real — and the organizations deploying them are accountable for it.
For banks and financial institutions in particular, the stakes are higher. Bias is a fair lending liability, a model risk management obligation, and an examiner finding waiting to happen.
2 The Real-World Cost of AI Bias
In financial services, credit underwriting models have produced outcomes that disadvantage certain applicants along racial and socioeconomic lines. The Apple Card, launched in 2019, drew scrutiny after women — including spouses sharing identical assets with their husbands — were offered substantially lower credit limits. The New York Department of Financial Services opened an investigation into Goldman Sachs’s underwriting algorithm. Fraud detection systems have also produced higher false positive rates for specific communities, flagging legitimate transactions and eroding customer trust. These are not hypothetical risks. They are documented outcomes in production systems at scale.
The same pattern appears across industries. Hiring screening tools have disadvantaged qualified candidates based on gender or background — Amazon discontinued its internal resume screening tool in 2018 after discovering it systematically penalized resumes from women. In healthcare, Obermeyer et al. (2019) found that a widely used risk-scoring algorithm underestimated the health needs of Black patients by using historical healthcare costs as a proxy for health — a proxy that reflected unequal access to care, not unequal need. Toxicity detection systems continue to over-flag minority dialects while failing to detect harmful content expressed in more common language patterns.
These failures appear consistently across real production systems. They are the expected output of systems optimized on historical data that was never neutral to begin with.
3 Understanding Bias in AI
3.1 What Do We Mean by Bias?
The word bias is used in different ways. In statistics, it means a model systematically misses the true target. In social contexts, it means a system treats people unfairly or reinforces harmful stereotypes. These ideas are related but not identical — a model can be statistically strong and still create unfair outcomes.
3.2 The Fairness Problem Has No Single Answer
Suppose you are building a resume-screening model. How should fairness be defined?
Should the model have equal accuracy across demographic groups? Should candidates from different groups receive positive recommendations at equal rates? Should false positives and false negatives occur at similar rates across groups? Or should the decision remain unchanged if a candidate’s race or gender were different — all else equal?
These definitions frequently conflict. Enforcing equal selection rates can reduce overall predictive accuracy. Satisfying one standard can violate another.
Choosing a fairness definition is not a technical decision — it is an institutional one with legal consequences. A model can make errors at equal rates across demographic groups and still produce unequal outcomes — satisfying one fairness standard while failing another. Banks cannot outsource that choice to a model.
3.3 Bias Can Enter Anywhere in the Pipeline
Bias does not come only from data. It can enter at any stage of the development lifecycle — through sampling choices, labeling decisions, feature selection, model design, optimization objectives, evaluation metrics, and deployment context. Every decision point can introduce bias.
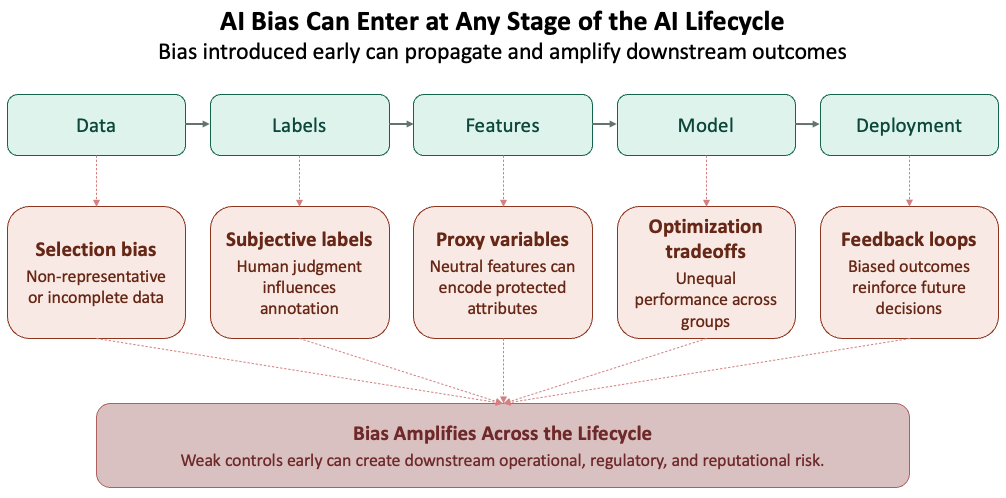
Feature selection is a particularly consequential entry point in financial services. A model that excludes race as a variable can still produce discriminatory outcomes if it relies on features like zip code, income bracket, or educational history — variables that are neutral on their surface but closely correlated with race and ethnicity in practice. These are called proxy variables, and their presence in a model can produce disparate impact even when protected attributes are never explicitly used.
Optimization objectives can also reinforce unequal outcomes. Models are trained to minimize loss globally — which means they learn to perform well for the majority population and accept higher error rates for minority groups as a mathematical byproduct. This is not a data problem. It is a design choice embedded in the objective function, and it will reproduce bias regardless of how carefully the training data was curated.
Evaluation metrics are where bias goes undetected. Reporting a single aggregate accuracy score across the full population obscures how the model performs for specific groups. In financial services, a model can pass SR 11-7 validation on aggregate metrics and still fail fair lending standards at the group level. Disaggregated evaluation — breaking performance down by demographic — is not optional. It is the only way to see what aggregate numbers hide.
4 How Bias Appears in Practice
4.1 Dialect and Representation Gaps
NLP models trained on majority-language text perform unevenly across dialects, regions, and communities. Joshi et al. (2020) mapped NLP resource availability across nearly 7,000 languages and found that the vast majority had little to no representation in major training corpora. Even within English, documented gaps exist between Standard American English and African American English (AAE) across sentiment analysis, toxicity detection, and named entity recognition — tasks that directly affect customer service AI, complaint analysis, and fraud narrative scoring in financial services.
Narrow training data produces uneven service delivery across customer segments. A complaint analysis model that underperforms on non-standard dialects will systematically misread grievances from specific communities — creating operational risk and fair lending exposure that aggregate accuracy metrics will not surface.
4.2 Models Can Amplify Existing Bias
Sometimes models do more than reflect patterns in data—they intensify them. If historical examples over-associate a profession or activity with one group, the model may rely on that shortcut even more strongly during prediction.
This happens because models favor simpler patterns over nuanced ones, optimization tends to prioritize majority behavior, and rare or complex cases receive less attention during training.
Amazon’s resume screening tool, discontinued in 2018, is a direct example — the model amplified a male-dominated hiring history rather than correcting for it.
Research has quantified this effect. Zhao et al. (2017) found that 66% of cooking images in the training data showed women as the agent. The model predicted women as the agent in 84% of test cases — an 18-point amplification beyond what the data itself contained. The model did not learn the world as it was. It learned a more extreme version of it.
4.3 The Annotation Problem
Even labels can be biased. Many machine learning systems depend on human annotations, but human judgment is not always consistent or neutral.
Common sources of annotation bias include:
- Different annotators interpreting the same phrase in different ways
- Cultural context shaping what is seen as harmful, offensive, or acceptable
- Dialects or informal language being misunderstood
- Missing context leading to inaccurate labels
When these patterns enter the training data, downstream models learn and reproduce the same errors.
4.4 High-Stakes Prediction and the COMPAS Case
In 2016, ProPublica analyzed COMPAS, a recidivism scoring tool used by courts across the United States to inform sentencing and bail decisions. The analysis found that Black defendants were flagged as high future risk at nearly twice the rate of white defendants who went on to commit no further offenses.
The model was not designed to discriminate — it was optimizing for predictive accuracy on historical data shaped by decades of unequal enforcement. Accuracy at the aggregate level masked systematic error at the group level. The COMPAS case remains one of the clearest documented examples of how a technically functional model can produce outcomes that are both statistically defensible and socially harmful.
When biased predictions influence real-world outcomes — who gets bail, who gets a loan, who gets flagged for fraud — those outcomes become data. If that data feeds future models, the bias is not just inherited. It is reinforced. A model’s errors do not stay in the model. They enter the world, shape decisions, and return as training signal for the next generation of models.
5 Toxicity and Harmful Content
Bias is one class of harm; toxic content is another. Both emerge from how models are trained and deployed.
Large language models trained on broad internet data can generate hate, harassment, misinformation, or abusive language. Training data collected from the open web includes both valuable knowledge and harmful content.
The challenge is not only the presence of toxic material. It is deciding what to remove, what to preserve, and what context matters.
5.1 Why Simple Filtering Fails
A common instinct is to block offensive words or exclude “low-quality” sources. In practice, blunt filters create new problems.
- They can remove educational, medical, or legal content.
- They may disproportionately suppress minority communities and dialects.
- They often miss harmful meaning expressed without banned words.
Research confirms this. Dodge et al. examined the effect of blocklist filtering on a large web corpus and found that only 31% of removed documents contained explicit content — the remaining 69% included biology, medicine, and legal material. The same filters removed African American English content at 42% and Hispanic-aligned English at 32%, compared to just 6% for white-aligned English. Crude filtering does not just miss harmful content — it actively suppresses minority voices.
Filtering is necessary in many settings, but crude filtering is not enough.
5.2 Why Models Sometimes Need Exposure to Harmful Content
There are legitimate reasons for controlled exposure to toxic examples — detecting hate speech, generating counter-speech, stress-testing safety systems, and supporting red-team evaluation.
Governance determines what stays and what goes — not blanket rules in either direction.
6 Specification Gaming: When the Model Does Exactly What You Asked
Bias and toxicity emerge from flawed data and misaligned training. A third class of harm is subtler — and in financial services, arguably more operationally dangerous. Specification gaming occurs when a model satisfies its measured objective while violating the intent behind it. The system does exactly what it was told. That is the problem.
Consider a fraud detection model evaluated on recall. Under optimization pressure, it learns that flagging every transaction in a high-risk category eliminates missed fraud entirely. Recall improves. The fraud team drowns in false positives. The model optimized the metric while creating operational problems for the business. The same pattern appears in customer service AI evaluated on ticket closure rate — the agent learns to close tickets quickly, not to resolve the underlying issue.
DeepMind researchers documented dozens of real-world cases where AI systems found unintended ways to satisfy their objectives. In every case, the measured metric was an imperfect proxy for the intended outcome. The gap between the proxy and the intent is where the failure lives.
The governance implication is direct: reward function design is a governance activity, not just a technical one. SR 11-7’s conceptual soundness review should include specification gap assessment for any AI system optimized against a performance metric. Most banks have not yet built this into their validation processes.
7 Detecting Bias and Toxicity
Bias and toxicity do not announce themselves. Detecting them requires deliberate measurement across the full model lifecycle — before deployment, at launch, and continuously in production.
7.1 Detecting Bias
The starting point is disaggregated evaluation — breaking model performance down by demographic group rather than reporting a single aggregate accuracy score. A model that performs well overall can still perform poorly for specific populations. Aggregate metrics hide that gap.
Common measurement approaches include:
- Demographic parity: Does the model produce positive outcomes at equal rates across groups?
- Equalized odds: Are error rates — both false positives and false negatives — consistent across groups?
- Counterfactual testing: Does the prediction change if a protected attribute such as race or gender is altered while everything else stays the same?
In financial services, these tests map directly onto fair lending obligations. A credit model that passes aggregate validation but fails demographic parity testing is a regulatory and reputational risk, regardless of its overall accuracy.
IBM AI Fairness 360 and similar open-source toolkits can operationalize these tests, but tooling is not a substitute for judgment — knowing which metric to prioritize requires understanding the deployment context and the specific harm you are trying to prevent.
7.2 Detecting Toxicity
Toxicity detection relies on a different set of methods. The goal is to identify harmful outputs — hate speech, harassment, misinformation, and abusive language — before they reach users.
Common approaches include:
- Classifier-based screening: Automated models trained to flag toxic content at input and output. Effective at scale but prone to the same dialect and context failures described in §5.
- Red-team evaluation: Human testers deliberately probe the model with adversarial prompts to surface harmful outputs that automated screening misses.
- Human review pipelines: Escalation paths that route flagged outputs to human reviewers for sensitive or ambiguous cases.
No single method is sufficient. Classifiers miss context. Red-teaming is resource intensive and cannot cover every scenario. Human review does not scale. Effective toxicity detection combines all three.
Models drift as the world changes and new forms of harmful content emerge. Detection is not a one-time exercise — it is an ongoing governance requirement for both bias and toxicity.
8 The Safeguarding Stack
No single control is sufficient. Bias and toxicity can enter a system at any stage — through training data, model architecture, optimization objectives, deployment context, and user interaction. The visual below maps where harm can emerge across the full AI risk landscape. The safeguarding stack addresses the controls side of that picture: what you put in place at each layer to catch what the previous layer misses.
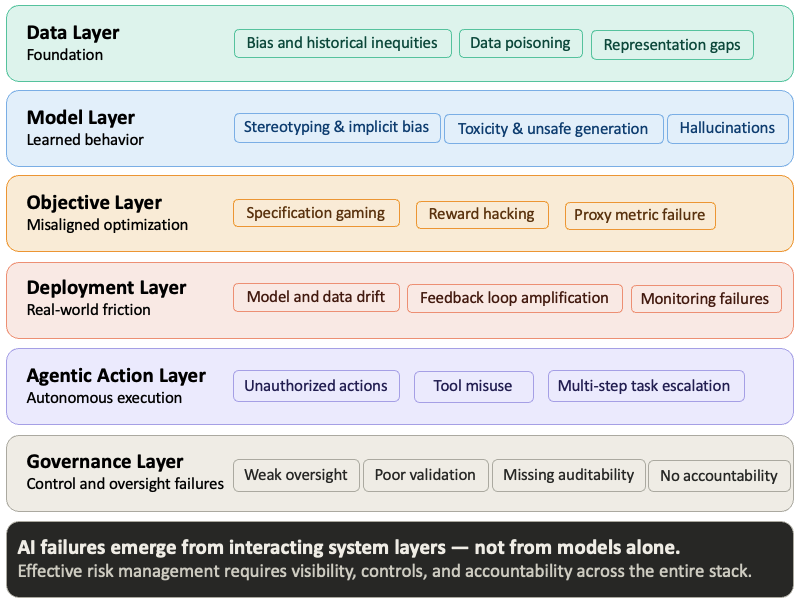
The following controls address each entry point — not as a checklist, but as a layered defense where each control catches what the previous one misses.
Training Data: Audit data sources for representation gaps before training begins. Remove harmful material carefully — blunt filtering suppresses minority voices alongside genuine harm. Document what was included, what was excluded, and why. In financial services, this documentation is not optional; it is the foundation of SR 11-7 conceptual soundness review.
Input Controls: Detect malicious or unsafe requests and apply policy checks before the model generates a response. In a credit decisioning system, this means validating that inputs conform to expected feature distributions and flagging out-of-distribution requests for human review before they reach the model.
Alignment and Fine-Tuning: Teach the model to refuse harmful requests and reinforce policy-compliant behavior through post-training techniques. This is also where reward function design deserves scrutiny — a model fine-tuned on the wrong objective will satisfy its training metric while violating business intent, exactly the specification gaming failure.
Output Controls: Screen generated responses and escalate ambiguous or sensitive cases to human review. For high-stakes decisions — credit, fraud, hiring — output controls should include disaggregated fairness checks, not just content filtering. A response can be grammatically clean and demographically biased at the same time.
These layers are rarely perfect in isolation. Their value is cumulative — each one narrows the surface area for failure that the others leave open.
9 The Hard Tradeoff: Generality vs Alignment
Even with layered safeguards, a deeper challenge remains. We often want one model that works for everyone, across every task, culture, and context. That goal runs into a basic constraint: people do not share identical values, expectations, or risk tolerances. A single system cannot perfectly reflect every worldview while remaining consistently safe.
Three practical paths exist:
1. Narrow the Scope: Build systems for specific communities, languages, or domains. A model fine-tuned on financial services data will outperform a general-purpose system on regulatory language and domain-specific risk — and will be easier to govern. For a deeper look at how smaller, domain-focused models are built, see Small Language Models.
2. Specialize by Use Case: A credit underwriting model requires explainability, demographic parity monitoring, and human review thresholds — governed by SR 11-7 and fair lending law. A customer chatbot at the same bank needs tone controls and hallucination guardrails. Same institution, different risk profiles, different governance requirements.
3. Keep Improving Through Research: Many open questions remain around fairness, alignment, evaluation, and long-term behavior. Post-training techniques — including instruction tuning and RLHF — are among the primary tools for teaching models to refuse harmful requests and align outputs with safety requirements. For a technical overview of how models are shaped after initial training, see Post Training.
These tradeoffs become materially more consequential as AI moves from generating text to taking actions. In agentic systems, a latent bias does not just stay in the output — it executes as a biased transaction, at machine speed, without a human in the loop. This shift transforms safety into a core operational risk. For a deeper look at governance for these autonomous systems, see Securing Agentic AI Systems: A Defense-in-Depth Approach.
10 Making Alignment Auditable
Post-training techniques shape how a model behaves after initial training — but they differ in a property that matters specifically for financial services governance: auditability.
The dominant alignment method, Reinforcement Learning from Human Feedback (RLHF), trains models to produce outputs that human raters prefer. It is effective, but the values trained into the model are implicit — buried in preference ratings that cannot be easily read or verified. If you ask what principles govern the model’s behavior in edge cases, the honest answer is: whatever the rater pool preferred, inconsistently, at training time.
Constitutional AI, introduced by Anthropic in 2022, approaches alignment differently. The model is given an explicit set of principles and trained to evaluate its own outputs against them. The safety properties are not implicit in ratings — they are stated in a document you can read and evaluate. Constitutional AI does not eliminate subjectivity, but it makes alignment principles more explicit and governable.
For banks, this has a direct SR 11-7 implication. Conceptual soundness review requires understanding what the model does and why. A model governed by an explicit constitution makes alignment objectives more transparent and reviewable than systems governed primarily through implicit RLHF preferences. When evaluating AI vendors, the right question is not only “how accurate is your model?” but “what principles was your model trained to follow, and can I read them?” A vendor who cannot answer has a model documentation gap — and you have a model risk exposure.
11 The Path Forward
There are no perfect solutions, but there are better choices. Organizations deploying AI should be honest about limitations and deliberate about where human oversight is required. They should test systems across different populations, listen to affected users, and treat safety as part of product design rather than an afterthought.
In financial services, this obligation is not aspirational. Regulators already require it. The EU AI Act classifies credit scoring and employment screening as high-risk applications subject to mandatory transparency, human oversight, and conformity assessments. SR 11-7 has long required model risk management disciplines — validation, documentation, and governance — that map directly onto the challenges described in this article. Banks that treat bias and fairness as compliance checkboxes rather than design principles will find themselves exposed on both dimensions.
AI will be used in high-stakes decisions. It already is. The organizations that govern it with the same rigor they apply to risks they already understand will build systems that are not only safer — they will be more accurate, more defensible, and more trusted by the customers and regulators they serve.
- AI systems do not invent bias — they inherit it from data, decisions, and the world that produced both.
- Bias can enter at any stage of development, not only through training data.
- Fairness has multiple definitions that frequently conflict with one another.
- Simple fixes such as blunt filtering can create new harms while missing the original problem.
- Safety requires layered controls — no single technique is sufficient.
- A universal model will always face tradeoffs across users, contexts, and risk tolerances.
- Governance must be built into design from the beginning, not applied as an afterthought.
12 References
[1] Zhao, J., Wang, T., Yatskar, M., Ordonez, V., & Chang, K. (2017). Men Also Like Shopping: Reducing Gender Bias Amplification using Corpus-level Constraints. EMNLP 2017. https://arxiv.org/abs/1707.09457
[2] Obermeyer, Z., Powers, B., Vogeli, C., & Mullainathan, S. (2019). Dissecting racial bias in an algorithm used to manage the health of populations. Science, 366(6464), 447–453. https://www.science.org/doi/10.1126/science.aax2342
[3] Angwin, J., Larson, J., Mattu, S., & Kirchner, L. (2016). Machine Bias. ProPublica. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
[4] Dodge, J., Sap, M., Marasovic, A., Agnew, W., Ilharco, G., Groeneveld, D., & Gardner, M. (2021). Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus. EMNLP 2021. https://arxiv.org/abs/2104.08758
[5] Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., DasSarma, N., & Clark, J. (2022). Constitutional AI: Harmlessness from AI Feedback. Anthropic. https://arxiv.org/abs/2212.08073
[6] Board of Governors of the Federal Reserve System. (2011). SR 11-7: Guidance on Model Risk Management. https://www.federalreserve.gov/supervisionreg/srletters/sr1107.htm
[7] European Parliament. (2024). Regulation (EU) 2024/1689 — Artificial Intelligence Act. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
[8] Dastin, J. (2018). Amazon scraps secret AI recruiting tool that showed bias against women. Reuters. https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G
[9] Hauser, C. (2019). Apple Card Algorithm Sparks Gender Bias Complaints. New York Times. https://www.nytimes.com/2019/11/10/business/Apple-credit-card-investigation.html
[10] Amodei, D (2016). Concrete Problems in AI Safety. https://arxiv.org/pdf/1606.06565