The Future of AI Isn’t Bigger — It’s Smaller
An Executive Introduction to Small Language Models (SLMs)
1 Introduction
For years, the AI industry chased a single dream — one massive model that could do everything. We went from 7 billion parameters to a trillion, racing toward a “God Model.” But in 2025, the wind has shifted. We are entering the era of Small Language Models (SLMs).
Small Language Models (SLMs)—compact, specialized AI systems typically under 10 billion parameters—are reshaping how organizations deploy AI. They’re not cheaper versions of GPT-4. They’re purpose-built engines designed for specific tasks, offering faster performance, lower costs, and better privacy controls.
This matters because the next wave of AI isn’t about chatbots. It’s about autonomous agents that make hundreds of decisions per transaction. And those agents need a different architecture—one where small, specialized models handle routine work while large models tackle genuine complexity.
2 What is a Small Language Model?
Think of SLMs as precision tools rather than Swiss Army knives. While large language models grew from 0.1 billion to 1.7 trillion parameters over seven years, small language models emerged in 2023 as a strategic optimization—staying in the 3-10 billion range while achieving comparable results on specific tasks.
A 7-billion parameter model fine-tuned for loan document extraction will outperform GPT-4 on that specific task—while costing 30 times less to run.
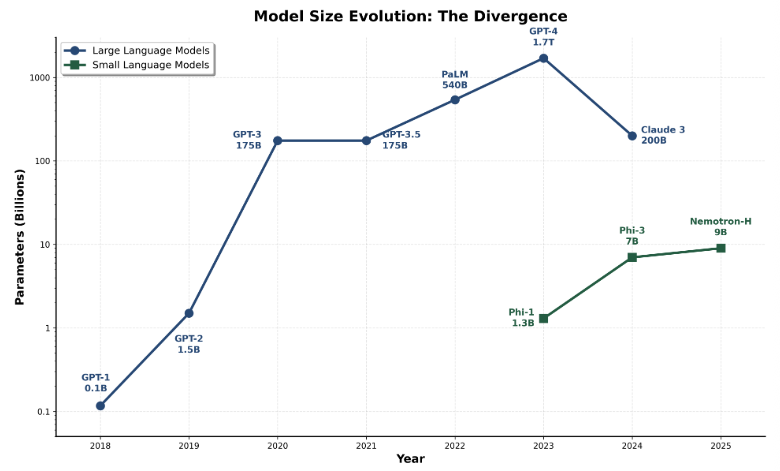
2.1 The Trade-Off: Breadth vs. Depth
Large models excel at versatility. GPT-4 can write poetry, debug code, and explain quantum physics in the same conversation. But using a 400-billion parameter model to extract dates from invoices is like hiring a philosophy professor to sort your mail — effective, but absurdly expensive.
Small models excel at efficiency. A 3-billion parameter model trained specifically on financial documents can’t discuss medieval history, but it will process loan applications faster and more accurately than a generalist model. Since it focuses on one domain, it delivers results in milliseconds rather than seconds—and at a fraction of the cost.
The economics are straightforward: if you’re running the same type of task thousands of times daily, specialized models make sense. If you need broad capabilities for unpredictable queries, large models remain essential.
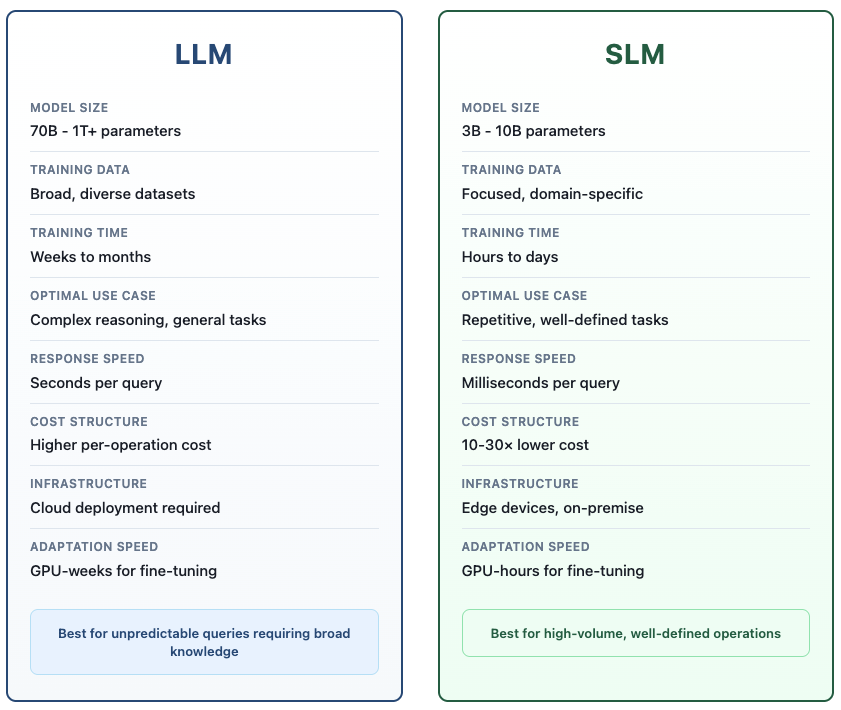
3 Proven Performance: SLMs Competing with LLMs
The performance gap between small and large models has closed. In head-to-head testing, 7-billion parameter models now match the performance of models 10 times their size—and specifically outperform them on specialized benchmarks.
Four examples demonstrate how far small models have come:1
Microsoft Phi-3 (7B parameters) matches 70-billion parameter models on code generation and language tasks. The difference? Phi-3 runs 15 times faster and costs a fraction to deploy.
NVIDIA Nemotron-H family (9B parameters) handles complex instructions as accurately as 30-billion parameter models while using one-tenth the computational resources. For high-volume applications, this translates to dramatically lower infrastructure costs.
Salesforce xLAM-2 (8B parameters) outperforms GPT-4o and Claude 3.5 Sonnet on tool-calling tasks—the ability to interact with external APIs. This is critical for agentic systems where precision matters more than poetry.
DeepSeek-R1-Distill-Qwen (7B parameters) beats Claude 3.5 Sonnet on math benchmarks (achieving 97.3% vs 78.3% on MATH-500). A 7-billion parameter model outperforming a flagship system on reasoning signals that the small-model approach has reached maturity.
The bottom line: Small models now deliver 95%+ accuracy at 10% of the cost for well-defined tasks.
4 The Scalability Problem
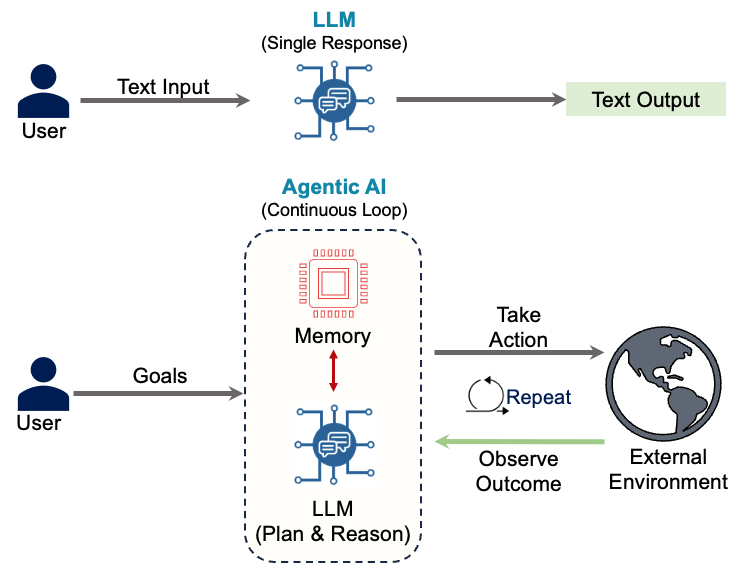
The shift to “Small” is driven by autonomous agents. Unlike traditional chatbots where a user asks a question and gets one answer, agents operate in continuous loops — planning, taking action, observing outcomes, and repeating. A single complex user request (e.g., “Plan my travel and book tickets”) might trigger 20 to 50 separate model calls as the agent checks calendars, searches flights, and parses API errors. If every one of those 50 steps uses a massive, expensive model (like GPT-4), the cost for a single transaction explodes. At scale, this becomes unsustainable.
4.1 The Solution: Heterogeneous Architecture
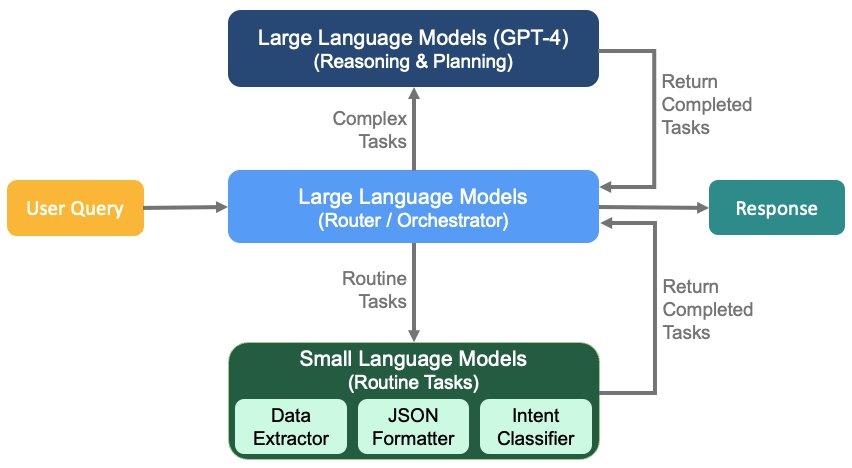
The answer isn’t using one model for everything. It’s using the right model for each task. In this approach, a large model acts as an orchestrator—understanding vague requests, planning the workflow, handling edge cases. Small models execute the routine steps: running database queries, formatting outputs, validating results.
This mixed approach cuts costs by 10-30× while improving reliability. Small models fine-tuned for specific tasks “hallucinate” less than generalist models attempting the same work.1
4.2 Why Agents Need SLMs
Here’s the economic challenge — Unlike traditional applications where a user submits a single query, agents make dozens of calls per request. A single request might trigger 20-50 model calls. When each call goes to a large model, costs compound rapidly.
Analysis of real agents (MetaGPT, Open Operator, Cradle) reveals that 60-70% of their model calls are repetitive, narrow tasks: parsing JSON, formatting API parameters, validating outputs, simple decision logic. These don’t need a 400-billion parameter model’s “world knowledge.” A 3-billion parameter model trained specifically for the task performs better and costs 30× less.1
5 How Do They Work?
Engineers use four advanced techniques to make small language models enterprise-ready. The first three—distillation, pruning, and quantization—create smaller models. The fourth, LoRA, enables rapid customization for specific tasks.
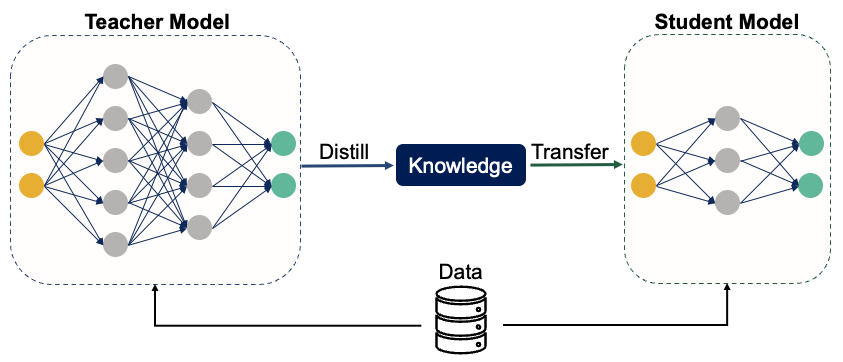
1. Distillation: A large “teacher” model generates millions of training examples. A small “student” model learns from these examples, absorbing the teacher’s problem-solving approach without inheriting its size.
2. Pruning: Like trimming a tree, engineers analyze the neural network to identify connections that don’t contribute to output quality. Removing these “dead branches” cuts the model size while preserving accuracy.

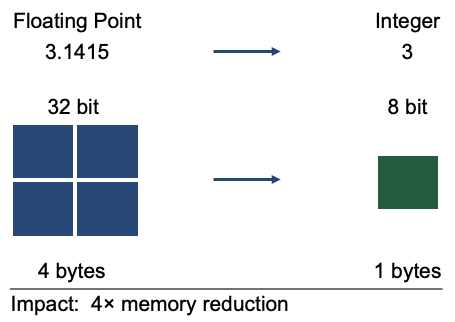
3. Quantization: Instead of storing numbers with high precision (3.14159), the model rounds them to simple integers (3). This reduces memory requirements dramatically—enabling powerful AI to run on laptops instead of servers.
4. LoRA (The Skill Plugin): The previous three techniques—distillation, pruning, and quantization—create small models. LoRA makes them practical for enterprise deployment. Here’s the challenge: A generic 7B model won’t excel at your specific banking tasks. You need one version fine-tuned for loan documents, another for fraud patterns, another for compliance reports. Traditional fine-tuning means retraining billions of parameters for each task—weeks of time and tens of thousands of dollars per customization. LoRA (Low-Rank Adaptation) keeps the base model frozen and trains only small adapter layers in parallel. By training just 1-2% of the model’s parameters, banks can customize models for specific tasks in hours instead of weeks — dramatically reducing both time and cost.
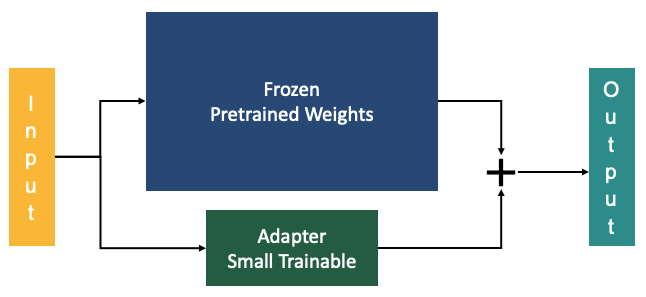
Why this matters for banking: Without LoRA, you’re forced to choose between generic small models (suboptimal performance) or expensive full fine-tuning (which defeats the cost advantage). LoRA gives you the best of both worlds: maintain the efficiency of small models while achieving task-specific performance through rapid, affordable adaptation.
6 SLM Examples
Six leading models from the current SLM landscape:
| Model | Best Use Case | Why? |
|---|---|---|
| Microsoft Phi-3.5 | Logic & Reasoning | Excels at math and analytical tasks. Ideal for agents that need to solve logic puzzles. |
| Qwen 2.5 (Alibaba) | Coding & Multilingual | State-of-the-art for its size; powerhouse for coding and non-English languages. |
| Meta Llama 3.2 | Mobile / Edge | Optimized for ARM processors (phones/tablets). Great for tool calling and strict instructions. |
| Google Gemma 2 | Creative NLP | Built on Gemini technology; strong in conversation and creative writing. |
| Mistral (Ministral) | Low Latency | Designed for extreme speed; ideal for instant-response applications. |
| IBM Granite 3.0 | Enterprise Coding | Trained on business software; excellent for RAG and structured coding tasks. |
7 Banking Applications
Financial institutions are particularly well-positioned to benefit from SLMs. Banking operations involve high volumes of repetitive, well-defined tasks that are perfect candidates for specialized small models.
7.1 Loan Document Processing
A regional bank processing 10,000 loan applications monthly has two options:
- The Old Way (LLM): GPT-4 at ~$2.50 per application costs $25,000/month.
- The SLM Way: A fine-tuned 3B model costs ~$0.10 per application, totaling $1,000/month.
The SLM, trained specifically on lending documentation, often delivers higher accuracy on domain-specific extractions like debt-to-income ratios, collateral valuations, and employment verification.
7.2 Real-Time Fraud & Compliance Monitoring
Banks need to screen every transaction for fraud. A massive cloud model is too slow and too expensive for this. An SLM can:
- Flag suspicious transactions in milliseconds
- Run entirely on-premise (no data leaves the bank’s secure network).
- Process 100,000+ transactions daily at a fraction of cloud API costs.
- Adapt overnight to new regulations via fine-tuning.
For privacy-sensitive operations, on-premise deployment eliminates the risk of sending customer data to external API endpoints.
7.3 Customer Service Triage
Instead of forcing every customer to wait for a “genius” AI, banks use a tiered system:
- The Front Line (SLM): A fast local model answers routine questions (“What’s my balance?”) instantly.
- The Escalation (LLM): Complex problems are routed to a larger reasoning model.
This hybrid approach delivers sub-second responses for most customers while maintaining quality for complex cases—all while reducing inference costs by 10-15×.
8 The Deployment Strategy
As discussed in Section 4, agentic AI requires a heterogeneous architecture. Most organizations implement this through a tiered approach that balances cost and quality.
- Level 1 (The SLM): A fast, cheap local model handles 80% of routine user queries in customer service scenarios—password resets, simple questions.
- Level 2 (The LLM): If the SLM detects a complex issue or gets confused, it “escalates” the ticket to a more capable cloud model like GPT-4.
This approach cuts costs by 10–30× while maintaining response quality. But the benefits go beyond economics. SLM-first architectures improve system speed, transparency, and privacy—three requirements that matter just as much in real-world deployments.
Latency: It’s not just about cost—it’s about speed. A local SLM can reply in under 200 milliseconds. A cloud LLM often takes 1–3 seconds. In customer service, that lag is the difference between a quick conversation and a frustrating wait.
Transparency: Large models are black boxes—it’s difficult to explain their decisions. SLMs are simpler, making it easier to trace their logic and satisfy regulatory requirements.
Privacy: SLMs can run entirely on-device. A phone can summarize notifications locally without sending data to the cloud, ensuring privacy and offline functionality.
8.1 The Deeper Economics of SLMs
The economic advantages extend beyond per-token pricing:
Inference Efficiency: Serving a 7B SLM requires 10-30× fewer FLOPs than a 70-175B LLM, enabling real-time responses at scale with dramatically lower energy consumption.
Fine-Tuning Agility: Full parameter fine-tuning for SLMs requires only GPU-hours versus GPU-weeks for LLMs. This means behaviors can be added, fixed, or specialized overnight rather than over weeks—critical for rapidly evolving business requirements.
Edge Deployment: SLMs run on consumer-grade GPUs, smartphones, and edge devices. For banks, this means processing sensitive data locally without cloud dependencies, reducing latency and strengthening data control.
Infrastructure Simplicity: SLMs require less or no parallelization across GPUs and nodes, lowering both capital expenditure for hardware and operational costs for maintenance.
8.2 Understanding the Barriers
Financial institutions face different barriers depending on their AI maturity:
8.2.1 For Early Adopters (Already Using LLMs)
Organizations that deployed LLM-based solutions face organizational inertia — they’ve built teams, workflows, and expertise around centralized models. Shifting to heterogeneous architectures requires retooling processes and adapting governance frameworks, organizational changes that take time.
8.2.2 For Institutions Just Starting
1. Governance & Compliance Uncertainty: Financial institutions face regulatory requirements for model explainability, validation, and risk management. While SLMs are actually more transparent than massive LLMs, most banks haven’t yet built AI governance frameworks. Starting with smaller, more auditable models is actually easier, but the perceived complexity of “AI governance” creates hesitation.
2. Lack of Banking-Specific Validation: Most published SLM case studies focus on tech companies or consumer applications. Regional banks lack peer examples showing successful SLM deployments in banking operations, credit decisioning, or compliance workflows. This slows adoption in risk-averse institutions.
3. Skills & Vendor Ecosystem: Unlike mature LLM platforms (OpenAI API, Anthropic), the SLM tooling ecosystem is less developed. Banks face uncertainty about deployment platforms, monitoring tools, and vendor support—increasing perceived implementation risk.
As organizations adapt their processes and banking-specific benchmarks emerge, these barriers continue to diminish.
The Strategic Choice: For banks beginning their AI journey, SLMs offer a clear path forward—lower costs, easier governance, on-premise deployment. For institutions already using LLM-based solutions, the transition to heterogeneous architectures requires systematic planning but delivers compelling ROI. The next section provides a practical implementation roadmap for both scenarios.
9 SLM Implementation Roadmap
Building a production-grade SLM solution—whether migrating from existing LLM agents or starting fresh—requires a systematic approach. Based on recent research from NVIDIA and Georgia Tech, here is a practical 6-step algorithm to identify exactly which parts of your agent can be downsized to an SLM.
Step 1: Start Logging Everything: You can’t optimize what you can’t measure. The first step is to capture every prompt, response, and tool call your current LLM makes. In a banking context, this means logging every time customer service bot classifies a transaction or resets a password. Make sure PII redaction is active before data hits your logs.
Step 2: Clean Your Data: Raw logs are noisy. You need to filter this data down to a high-quality training set — aim for 10,000 to 100,000 examples (for LoRA fine-tuning; full fine-tuning may require more). Remove any “I don’t know” responses, hallucinations, or failures. You want your new small model to learn only from your current model’s wins, not its mistakes.
Step 3: Find the Patterns: Analyze the data to find repetitive tasks. You will likely find that 60-70% of your agent’s work falls into narrow buckets. For example, your “General Banking Assistant” might actually spend half its time just formatting JSON for an API. This is the perfect candidate for a small model.
Step 4: Pick Your Model: Pick an SLM that fits the specific task you identified.
- For reasoning tasks: Look at Phi-3 or DeepSeek-R1-Distill.
- For strict formatting: Look at highly quantized versions of Mistral or Llama 3 8B.
Step 5: Fine-Tune (The Transfer): This is the critical step. Use LoRA (Low-Rank Adaptation) to fine-tune your chosen small model using the clean data from Step 2. You are effectively teaching the small model to mimic the large one, but only for that specific task. It doesn’t need to know French poetry; it just needs to know how to handle that specific banking API.
Step 6: Evaluate, Deploy, and Monitor: Test your fine-tuned SLM against the baseline LLM on a held-out test set before deployment. Validate that accuracy matches or exceeds the LLM for your specific task. Once confirmed, launch the SLM as a specialized worker with automatic fallback to the larger model when confidence is low. Monitor task completion rates (>95%), fallback frequency (<20%), and cost savings (10-30×) to continuously improve performance.
For Banking Deployments: Document your model selection rationale, training data sources, and validation methodology to satisfy model risk management requirements. SLMs’ smaller size and task-specific nature make governance easier than LLM deployments.
10 Conclusion
The industry spent years chasing bigger models. Now we know better.
What changed? We’ve moved from trying to build one massive “God Model” that does everything to using specialized models for specific jobs. The data is clear: small models handle 60-70% of AI tasks, cost 10-30× less, and often work better than the giant models on focused operations like loan processing or fraud detection.
Why banks should care: You can run these models on your own servers — no customer data leaves your building. Regulators can actually understand how they make decisions. When rules change or you launch new products, you can retrain them in hours, not months.
Is this real? Yes. Microsoft, Meta, Google, and Alibaba all ship small models that work in production right now. Banks are already using them. The techniques —distillation, pruning, quantization, LoRA — aren’t experimental anymore. The obstacles you’ll hit are organizational (getting teams aligned, updating governance) not technical.
Why now matters: Banks moving first lock in a 10-30× cost advantage that’s hard for competitors to match later. Waiting for “just a bit more proof” means spending the next two years at legacy costs while watching others operate leaner.
The “God Model” era is over. The precision tool era has begun.
11 References
[1] Belcak, P. et al. (2023). Small Language Models are the Future of Agentic AI. https://arxiv.org/pdf/2506.02153
[2] Lu Z. et al. (2025). Small Language Models: Survey, Measurements, and Insights. https://arxiv.org/pdf/2409.15790
[3] The Economist. (2025). The bigger-is-better approach to AI is running out of road. https://www.economist.com/science-and-technology/2023/06/21/the-bigger-is-better-approach-to-ai-is-running-out-of-road
[4] Nvidia. (2025). How Small Language Models Are Key to Scalable Agentic AI. https://developer.nvidia.com/blog/how-small-language-models-are-key-to-scalable-agentic-ai/